1.配置环境
- 系统:windows 10 64位
- GPU:GTX1080
- CUDA:9.0
- cudnn:7.0
- Python:Anaconda 2.7 version
- 编译:Visual Studio 2013
2.安装CUDA和cudnn
1 | CUDA各个版本下载地址:https://developer.nvidia.com/cuda-toolkit-archive |
3.下载并编译caffe-ssd-microsoft
网上很多是通过caffe-windows编译修改成ssd版本,这里推荐使用caffe-ssd-microsoft版本1
下载地址:https://github.com/conner99/caffe //选择ssd-microsoft分支
a. 配置修改
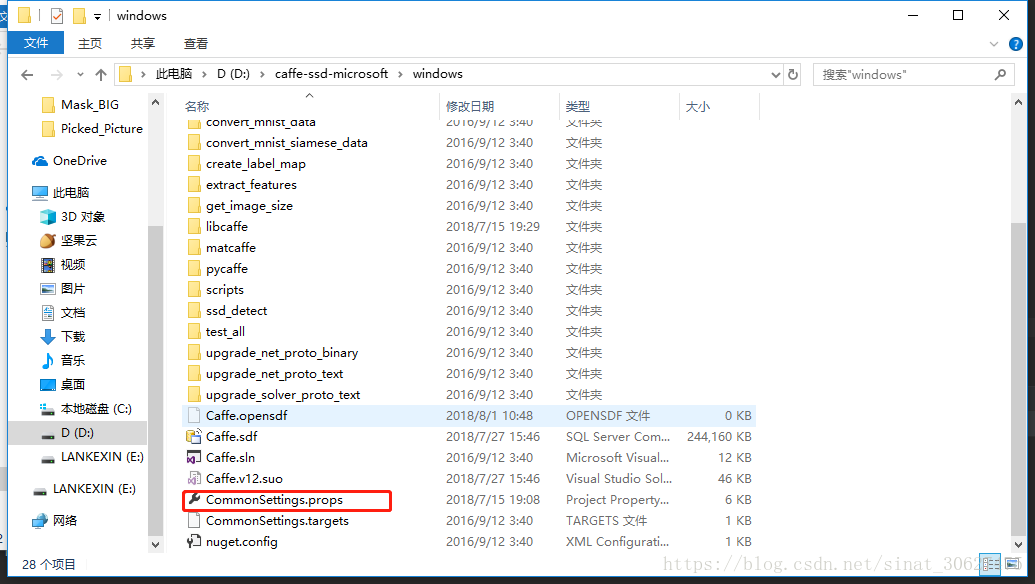
- 打卡windows文件夹,找到CommonSettings.props.example文件,备份,然后更改文件名为CommonSettings.props,然后使用VS2013打开Caffe.sln文件;
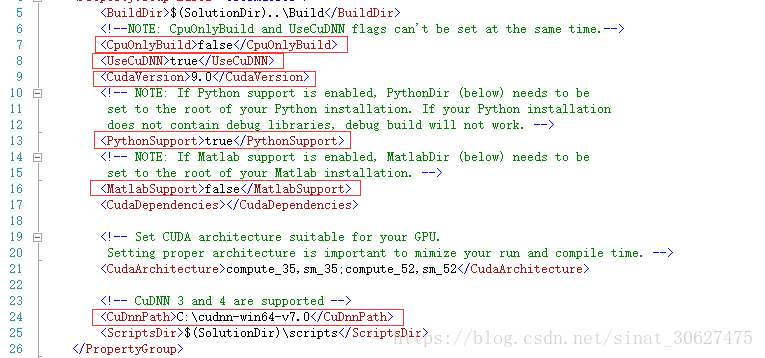
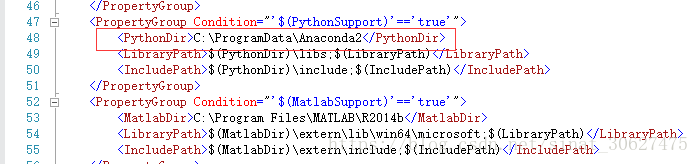
- VS中打开CommonSettings.props配置文件,然后修改以下配置,其中第24行为先将下载的cuDNN文件解压得到cuda文件夹,此行为cuda文件夹路径,第48行为Anaconda2安装文件夹路径;
- 此时若发现libcaffe & test_all未加载成功,关闭VS,然后打开CUDA安装路径下的MSbuildExtensions文件夹,拷贝该文件夹下的所有文件到C 盘 / Program File(x86) /MSBuild /Microsoft.Cpp /v4.0(这里取决于你安装的版本) /V120 / BuildCustomizations 文件夹,替换目标中的文件;
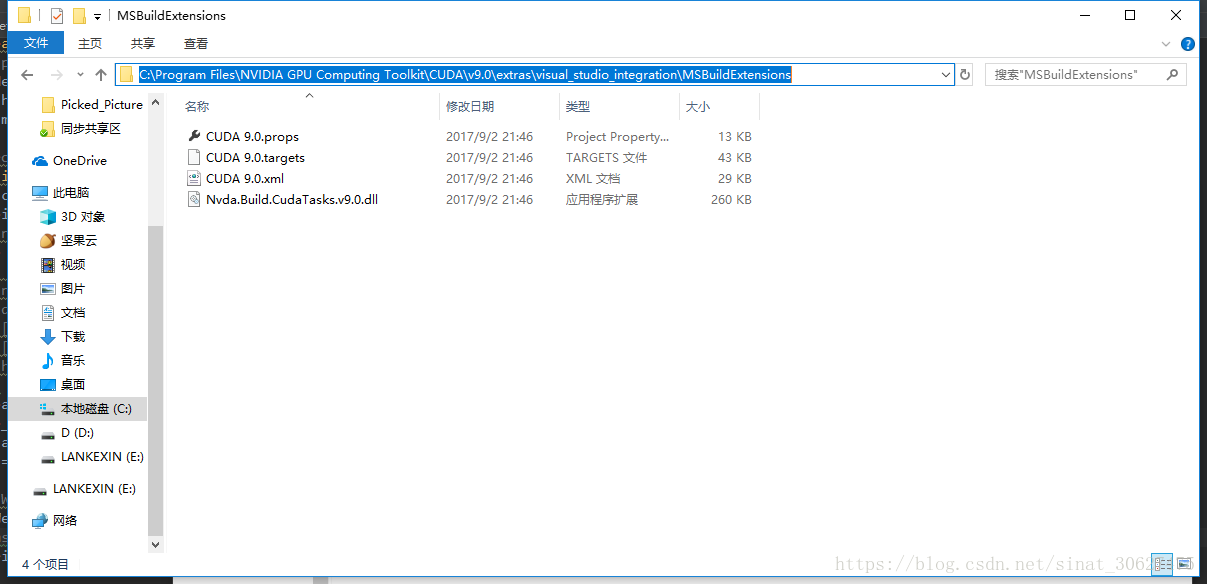
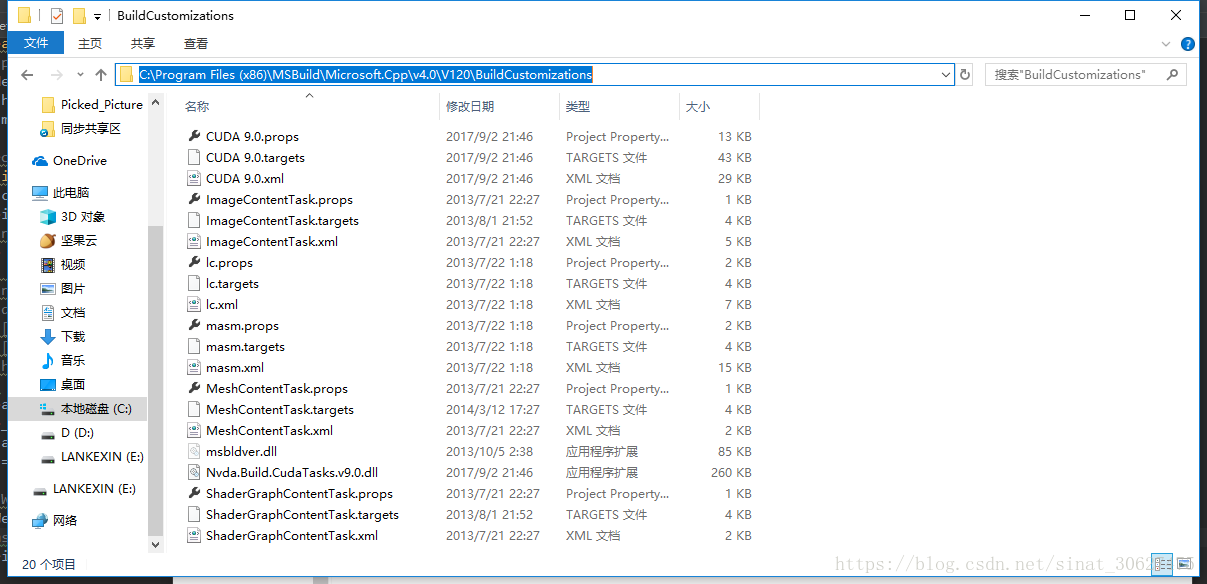
- 重新打开VS即可看到加载成功
b. 编译
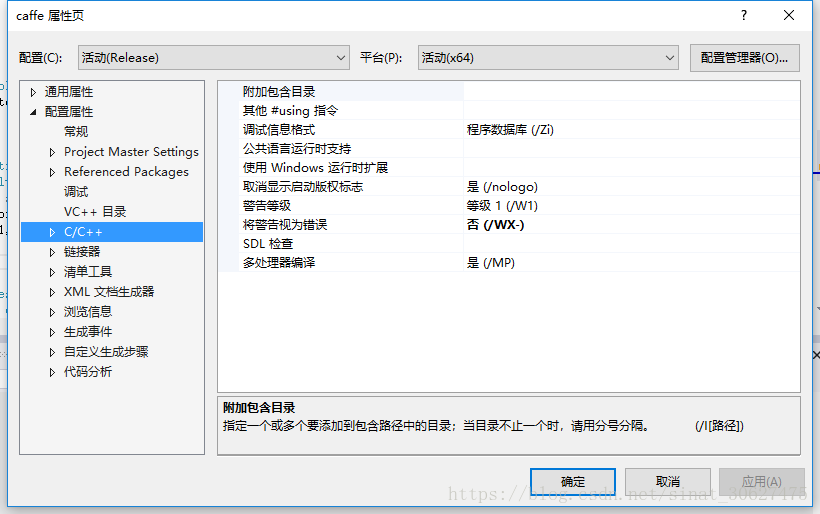
- 首先编译libcaffe,设置libcaffe的属性页如下图所示:
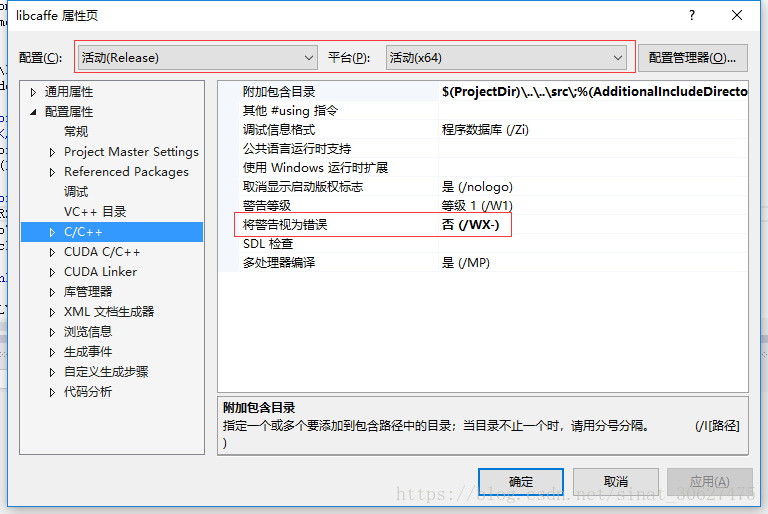
- 编译libcaffe,会出现与boost相关的regex正则表达式库问题,项目中不需要,注释掉即可,即进入libcaffe中,搜索detection_output_layer.hpp /detection_output_layer.cpp /detection_output_layer.cu文件中所有的含有regex和rv的代码注释掉
- 可能会出现expected an identifier in caffe.pb.h,出现与thrust相关的问题,打开bbox_util.cu文件,搜索并注释掉所有含thrust的语句
- 在路径.\caffe-ssd-microsoft\include\caffe\3rdparty\下添加hungarian.h文件,在路径.\caffe-ssd-microsoft \src \caffe \3rdparty \下添加hungarian.cpp文件;在这里找这个文件,链接:http://pan.baidu.com/s/1mhYuf7y 密码:3jp2
- 另外在编译过程中可能会出现一些依赖包的问题,常见的是opencv和gflags的问题显示为:
error MSB4062: 未能从程序集 D:\NugetPackages\OpenCV.2.4.10\build\native\private\coapp.NuGetNativeMSBuildTasks.dll 加载任务“NuGetPackageOverlay”。未能加载文件或程序集“file:///E:\NugetPackages\OpenCV.2.4.10\build\native\private\coapp.NuGetNativeMSBuildTasks.dll”或它的某一个依赖项。系统找不到指定的文件。 请确认
声明正确,该程序集及其所有依赖项都可用,并且该任务包含实现 Microsoft.Build.Framework.ITask 的公共类。D:\NugetPackages\OpenCV.2.4.11\build\native\OpenCV.targets1115 5 libcaffe
- 我在解决opencv问题时候发现解决这个问题的方法可能会是多种的,我的问题是在Github的issue中找到的解决方法,设置最大运行和编译数量为1
1 | https://github.com/BVLC/caffe/issues/4788 //我使用了最后一个解决方法 |
- 你的问题说不定会在issue的其他解决方案中找到答案,另外有人提出在NugetPackages \OpenCV.2.4.10 \build \native \OpenCV.props文件中修改删除private前面的’\’可以解决,另外一个麻烦一点的解决方法是删除自动下载的opencv包,然后手动配置各个项目的opencv依赖,参考博客如下:
1 | https://blog.csdn.net/qq_27278153/article/details/53667756 |
- 对于gflags也可以参照opencv的做法来尝试解决
- 编译libcaffe还遇到的一个问题是提示 error MSB3721: 命令“”C:\Program Files \NVIDIA GPU Computing Toolkit \CUDA \v6.5 \bin\nvcc.exe” 后面跟了一大堆参数,其实出现这个问题主要是由于另一个问题引起的,即too few arguments···,全局搜索找到cudnnSetConvolution2dDescriptor函数(位于cudnn.hpp),为该函数增加一个参数:

- libcaffe编译成功之后,接下来就要编译caffe,编译caffe同样要设置属性页
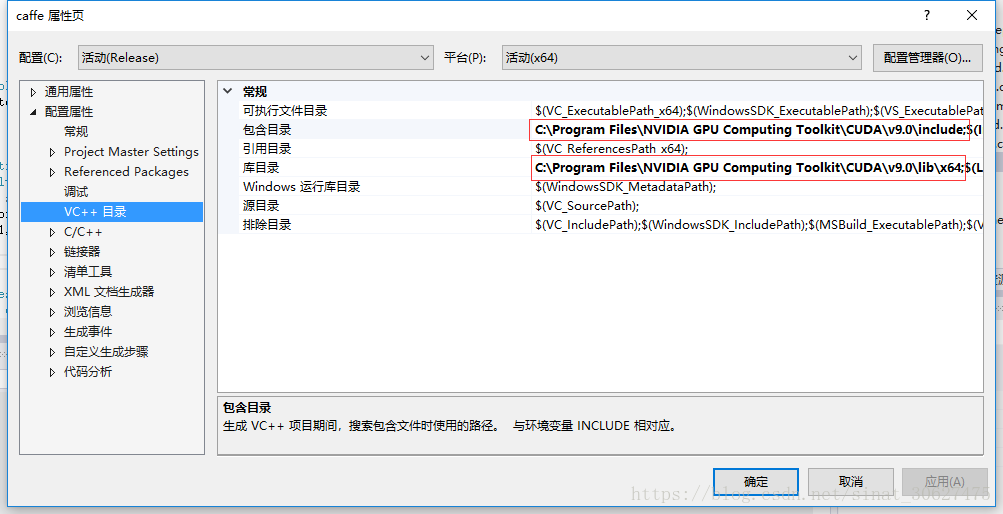
- caffe项目在编译过程中可能会出现cuda相关库找不到的问题,此时在caffe属性页将安装的cuda路径添加到VC++目录中去:
- 编译完caffe项目之后即可编译pycaffe项目和convert_imageset项目,相应的也要设置属性页中的VC++目录
c.模型训练
- 在编译完成之后就可以进行模型的训练过程,模型训练过程中可能还会有一些问题,遇到之后再回来更改重新编译
- 首先准备好自己的数据集,图片和文本文件,然后新建一个bat文件,作用是将数据集转换成模型训练需要的lmdb格式,双击运行即可
1 | D:\caffe\Build\x64\Release\convert_imageset.exe --resize_height=300 --resize_width=300 --shuffle --backend=leveldb D:\caffe-ssd-microsoft\data\VOC0712\train\ D:\caffe-ssd-microsoft\data\VOC0712\train.txt D:\caffe-ssd-microsoft\examples\myfile\VOC0712_trainval_lmdb |
- lmdb文件生成之后,修改solver/test/train的三个网络文件,修改路径,然后新建一个bat文件,作用是训练数据生成模型,双击运行即可
1 | SET GLOG_logtostderr=1 |
- 模型训练中会出现distort_param / expand_param等参数无法被解析,这是由于从linux系统移植到windows系统下出现的参数问题,我的解决方法是对照之前linux系统下的caffe.proto文件,将无法解析的参数部分复制过来添加到目前系统下的caffe.proto文件(位于./caffe-ssd-microsoft/src/caffe/proto),然后重新按顺序编译,之前看到博客有建议说直接将这个文件复制过来替换现在的文件,但是替换之后编译会在多个文件报错,需要把报错文件都替换,所以我的做法是对比只添加未能解析的参数,然后重新编译工程,这个过程可能会浪费一些时间尝试
d.Python图像识别
- 训练生成模型之后,就可以通过模型文件来做图像识别,我主要用的是Python,通过python调用caffe包来做识别
- 首先将之前工程生成的./Build/x64/Release/pycaffe文件夹下面的caffe文件夹复制到Python的包目录下,即./Anaconda2/Lib/site-packages下面,然后在命令行下输入python/import caffe,执行成功则说明pycaffe编译成功
- 将原linux下的python程序移植到windows基本没遇到什么问题,需要修改一下路径,然后我遇到的一个问题是有一个包VDBSCAB在windows下无法安装,我的解决办法是直接通过原linux系统将该包复制过来添加到python的包目录下即可
- 至此Caffe-ssd版本从linux系统下移植到windows完成。